Python Exploration
This page has been updated on July 1st, 2023 using a slightly different setup. Check it out here.
Hello, welcome to the text analysis code tutorial. From here, I will be walking you through how to utilize the code in order to utilize the results for your own analysis.
What this code does is pull data from the data set you provide (for example, the descriptions in the full data sheet for this project), as the input and outputs values counting the frequency of words within the set. This output can be used for multiple avenues of analysis some of which will be demonstrated in examples further down.
Please do note, you must download software for this to work. The code was written with the assumption that the user has Anaconda downloaded. (You can find that here.)
If you already have Python and no desire to download Anaconda, please do note that the code uses packages such as the Natural Language Toolkit and Pandas which will needed to be downloaded individually. If you do have Anaconda, there is no need to download these as they are included.
Once you have the necessary software downloaded, you will need to make some alterations to the code to allow it to work with your dataset. The sections where the changes must be made will be denoted in bold.
- For the line labeled "file", the location of the file must be adjusted to match that of the dataset on your device. Additionally, the sheet name must be changed to match the sheet name in your Excel file.
- The name(s) of the columns of the sheet in which the data is contained may need to be changed. Do note that this variable ("Transcription of Description") repeats throughout the code and will need to be adjusted everywhere within the code for it to work. It is faster to change the names on your Excel sheet to match the code.
- You may want to adjust the name of the output Excel file to fit your needs, especially if you are planning to run the code multiple times for multiple sets of descriptions.
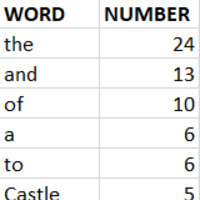 The output of the code should theoretically give you a list of significant words and their frequency. This means that words such as the, and, or, but, and so should be excluded while things such as soil or island should be. Due to the time period the sources were written and the evolution of spelling in the English language, it is possible that some instances of these words might not be caught as they do not match the modern spellings and thus will need to be removed from your results sheet manually.
The output of the code should theoretically give you a list of significant words and their frequency. This means that words such as the, and, or, but, and so should be excluded while things such as soil or island should be. Due to the time period the sources were written and the evolution of spelling in the English language, it is possible that some instances of these words might not be caught as they do not match the modern spellings and thus will need to be removed from your results sheet manually.
For example, this one quote without these words removed has "the" as the most frequently occurring word. The first word that is not an article or preposition is the sixth most frequent word, "Castle."
As this is a singular quote, I am not pulling broader significance or analysis from that. Though, based on the frequency chart with the stopwords removed, we may realize that Gage was describing a structure that appeared like a castle. In this case, the Castle of San Juan de Ulúa.